|
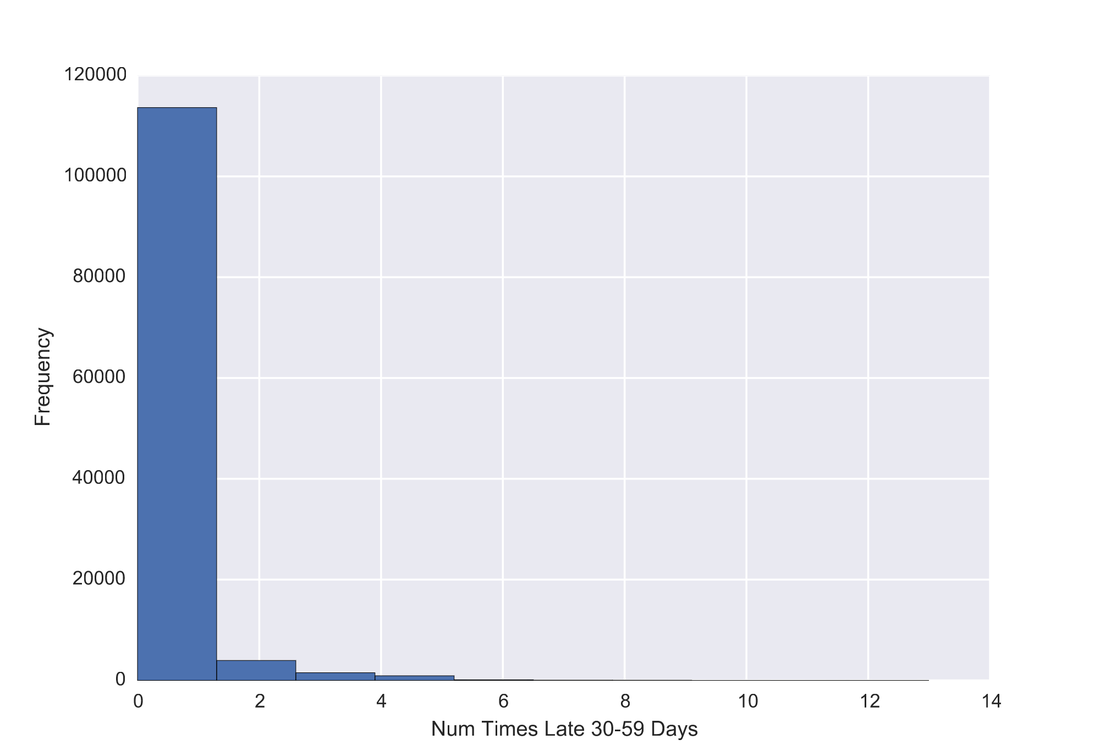
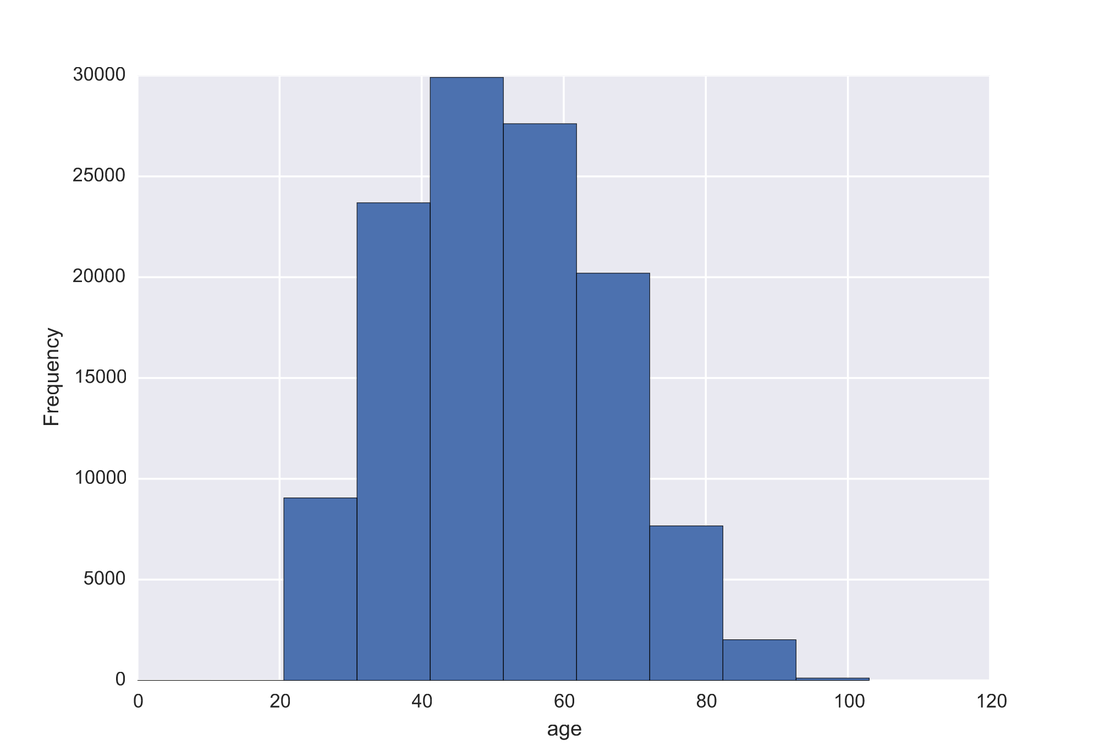
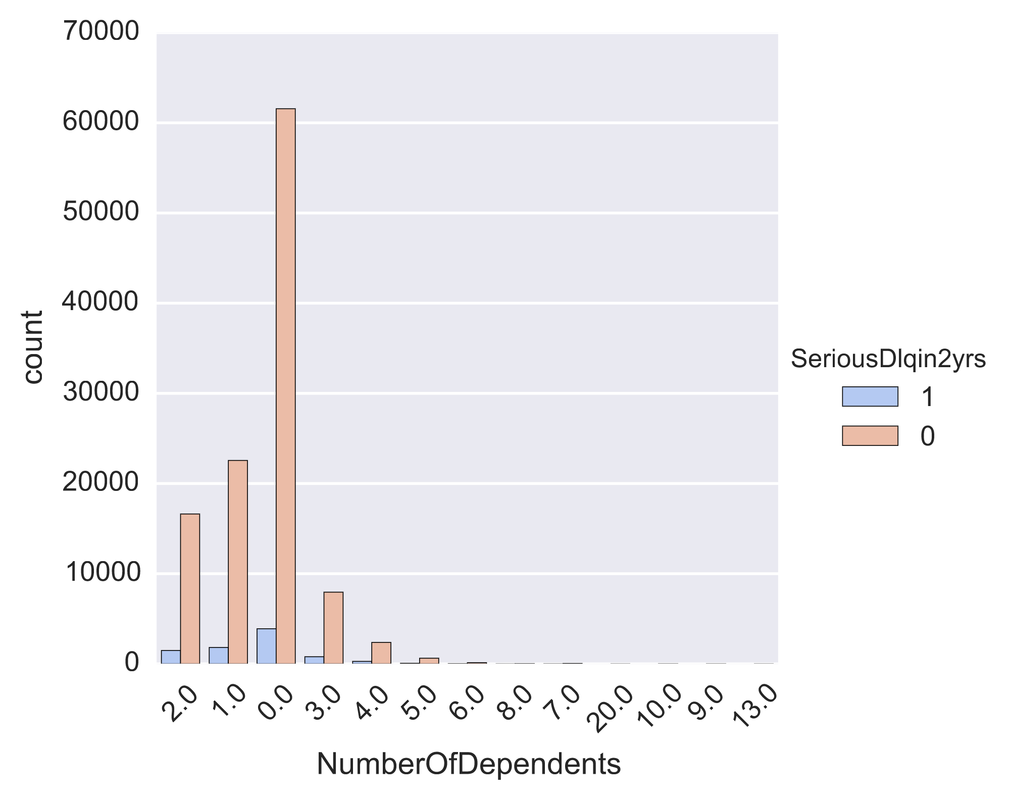
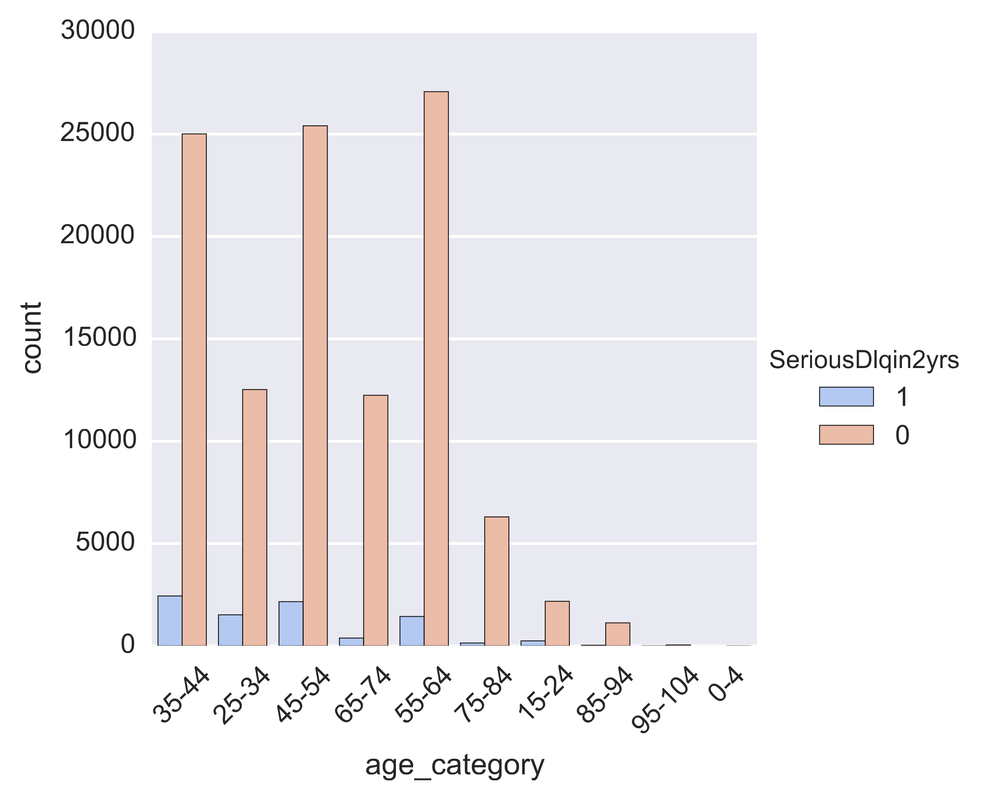
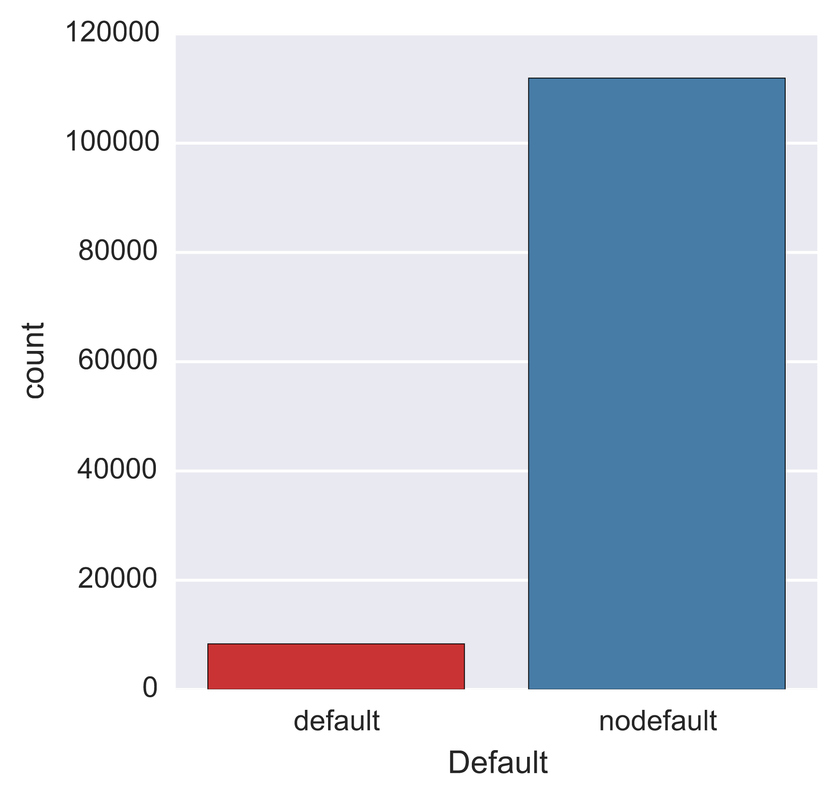
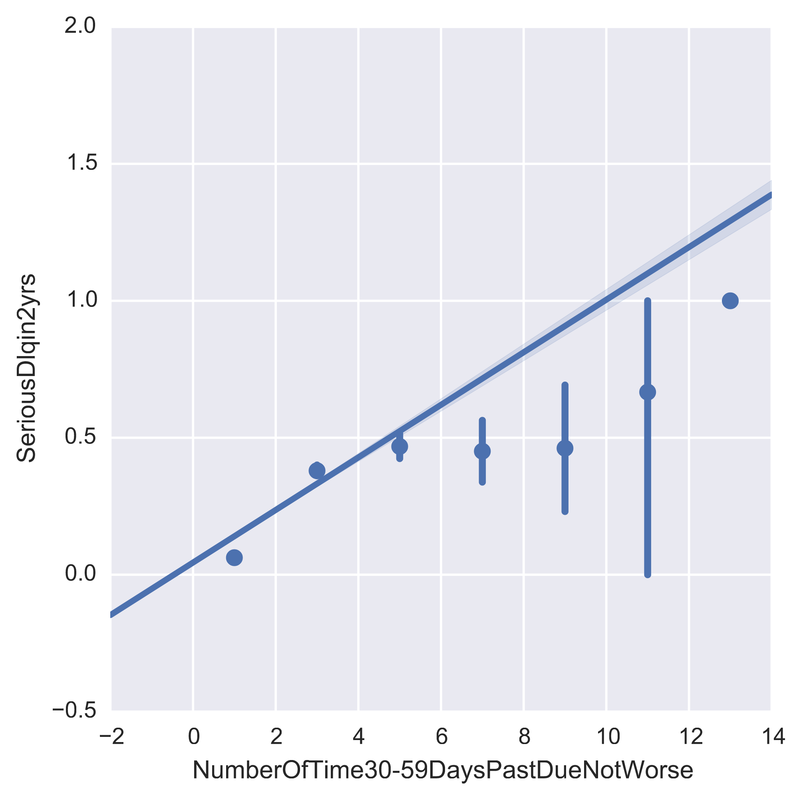
One problem banks are interested in is determining the credit score of their customers in order to predict the likelihood that their customers would default on a potential loan. In this blog post I will talk about the project I worked on that dealt with this problem. I obtained data from: https://www.kaggle.com/c/GiveMeSomeCredit I used Python to work on this data set. I started with Logistic Regression to carry out my analyses. Because the training set had lots of NA values, I first got rid of the entries that contained any NA values The "30-59DaysPastDueNotWorse" variable contained values 96 and 98, which are typos, so I replaced them with the median of 30-59DaysPastDueNotWorse I then generated histograms of the 'age' and 'NumberOfTime30-59DaysPastDueNotWorse' variables I then generated a KDE plot to further visualize the data. The KDE plot is similar to a histogram in that it treats each data point as a Gaussian distribution and then takes the cumulative probability function 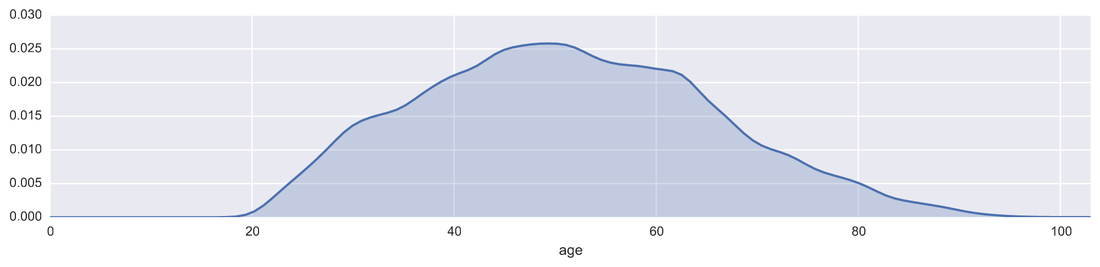 I also wanted to generate plots that show how many of the entries contained defaults and non-defaults, along with factor plots (using the Seaborn package) that shows how the defaults varies depending on the age and number of dependents of each person I then generated linear plots using Seaborn to see how the number of defaults correlates with the 'NumberOfTime30-59DaysPastDueNotWorse' variable I then proceeded with Logistic Regression. I first set the dependent variable as the defaults and converted it into a 1-d array as required by Scikit-learn I then computed the score by using Logistic Regression on the entire training set. I obtained a score of 93.06%. However, this was only a marginal improvement from the actual percentage of non-defaults in the dataset, which is 93.05% To improve on this score, I then tried Regularization with the Lasso l1 penalty. I then split the training set into a training and validation/test set. Python automatically converts 75% of the original set into a new training set and the remaining 25% becomes the validation set. The plot below shows the coefficients as a function of the log of C (where C=1/lambda, where lambda is the penalty term. The greater the lambda, the more the coefficients of the predictors tends towards 0, thus eliminating the irrelevant predictors) 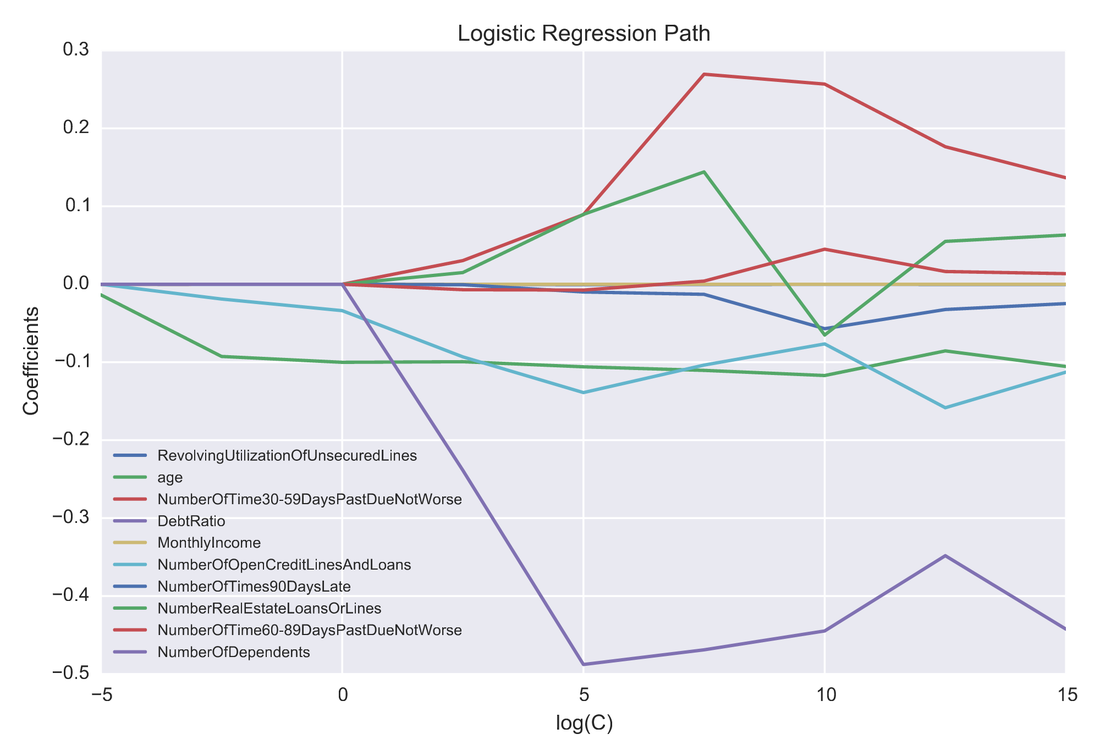 Many of the coefficients go towards 0 when C=0 (or lambda = inf). The accuracy scores I obtained were 1.0 for C values = 1, 316.2, 100000, 3.16e7, etc. However, the score was .9301 when C=1e-5 and .99963 when C=.003 (logC = -2.5). From the plot, it is hard to determine which predictors become 0 due to increasing C. I concluded that the most relevant predictors were DebtRatio, age, NumberRealEstateLoansOrLines, and NumberOfOpenCreditLinesAndLoans.
I then used only these relevant predictors in another Logistic Regression analysis. However, with just these predictors, the accuracy dropped to .9277 For future studies, I plan to utilize Random Forest and Support Vector Machine to compare the accuracy score with Logistic Regression. I also want to see if using an ensemble of these methods can further improve the accuracy score Full details of the code at: https://github.com/jk34/Kaggle_Credit_Default_Loan
0 Comments
Leave a Reply. |
AuthorHello world, my name is Jerry Kim. I have a Master's Degree in Physics and years of work experience in Image Processing, Machine Learning, and Deep Learning. I mostly have used C++, Matlab, and Python. I created this website to showcase a small sample of the things that I have worked on Archives
March 2017
Categories |
 RSS Feed
RSS Feed
